今天刷arxiv时候发现一个很有意思的数据集「CC-Riddle」–汉字谜语问答数据集,分享给大家。论文全称《CC-Riddle: A Question Answering Dataset of Chinese Character Riddles》。
paper地址:https://arxiv.org/pdf/2206.13778.pdf
github地址:https://github.com/sailxuOvO/CC-Riddle介绍
汉字谜语是一种以单个汉字为答案的猜谜游戏。谜语描述通常是根据谜“字”的发音、形状或解释来创作的,并使用典故、双关、隐喻等手法,使得谜语的解谜具有挑战性。
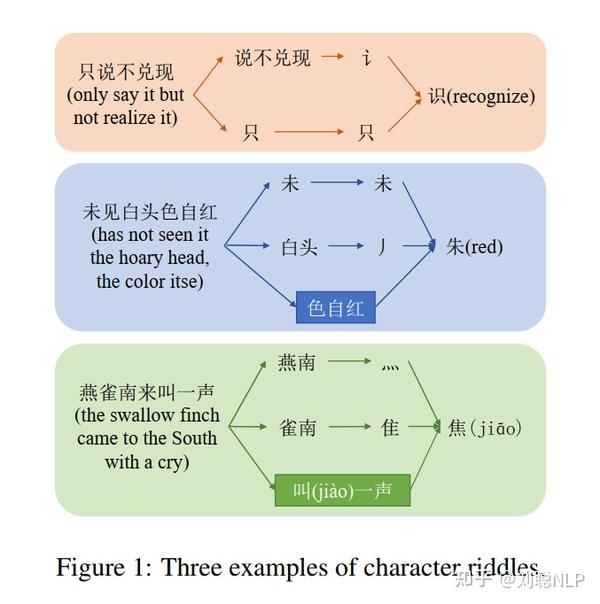
该论文通过从网上爬取和模型生成两种方法,构建了包含大部分常用简体字的汉字谜语数据集,并给出了一个汉字杰迷的QA系统,发现现有模型效果均不理想。
数据集构建
数据集由两部分构成:(1)网络爬取;(2)模型生成。
针对网络爬取,从猜谜谷中抓取了20392个不同的汉字谜语,共涉及5066个汉字。
针对模型生成,通过汉字机构、汉字拼音和汉字源解。汉字按结构分共包含10种,分别为独体、上下、上中下、左右、左中右、上单、下单、左单、右单和包围结构类型。
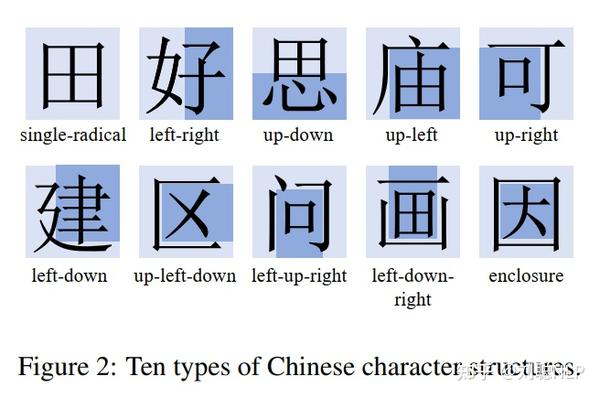
通过IDS字典和HanziCraft将汉字进行粗细粒度拆解,如下图所示,

通过新华词典获取汉字的解释,由于解释的篇幅过长,例句较多,因此只采用词典中解释的前几句作为该汉字的注解。
采用BART模型进行谜语生成,解码器的输入包括:汉字、拼音、粗粒度汉字结构、细粒度汉字结构和汉字注解,并使用[SEP]进行分割。模型超参数如下:学习率为5e-5,批大小为16,随机种子为42,epoch个数为12。
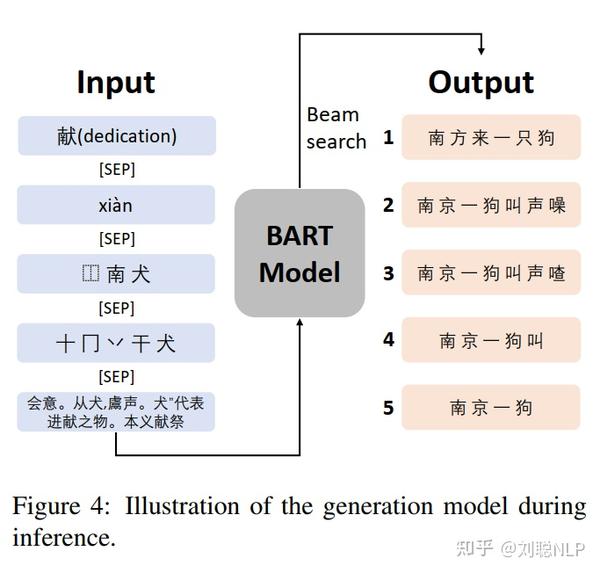
对生成的候选集合进行人工筛选,最终生成了7132个谜题。

数据集分析
- 覆盖率:CC-Riddle数据集共包含27524个谜语,包含7285个汉字,简体字覆盖率为89.8%。
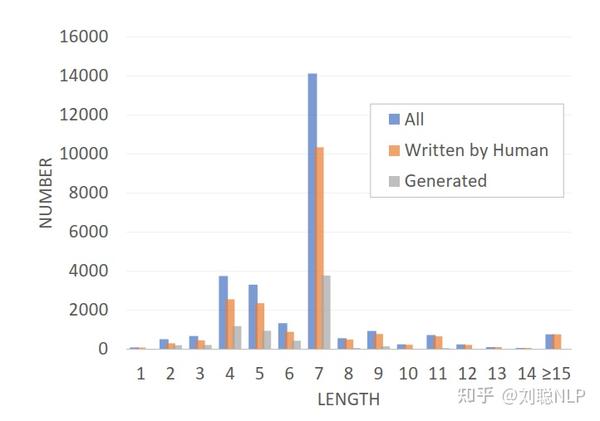
- 长度:数据集中模型生成的字谜长度与人工字谜长度分布基本一致。
- 单字多谜语:CC-Riddle数据集中绝大多少的汉字仅有一个谜语描述,很少有汉字有超过10个谜语描述。
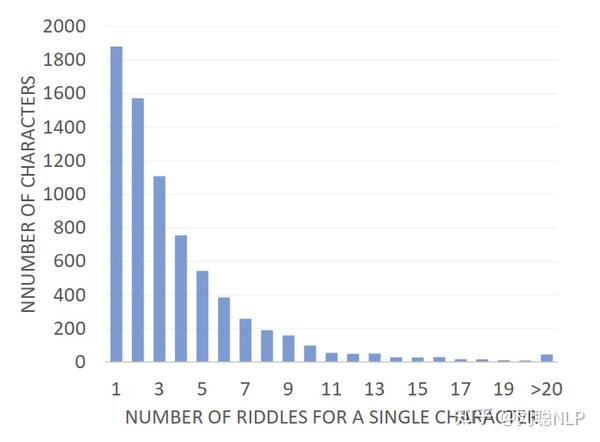
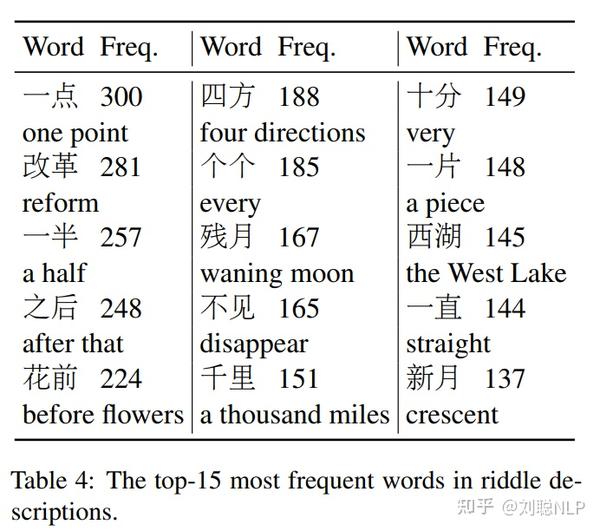
- 词频:谜语描述中经常出现一些词,在一定程度上代表了汉字谜语的语言风格,通过jieba分词后,top15的词如下:
- 难度:人类书写的文字谜语比模型生成的谜语往往更有技巧和挑战性。
QA系统
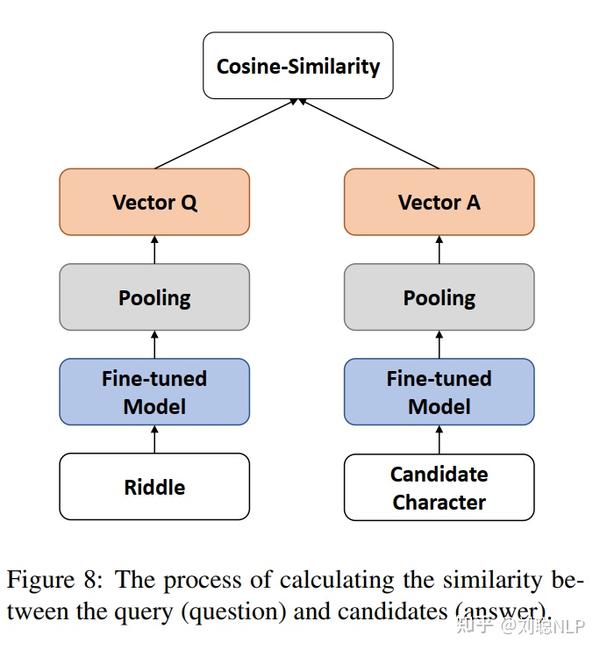
通过Sentence-Transformers模型对谜语(query)和汉字(answer)分别进行编码表示,计算其余弦相似度。
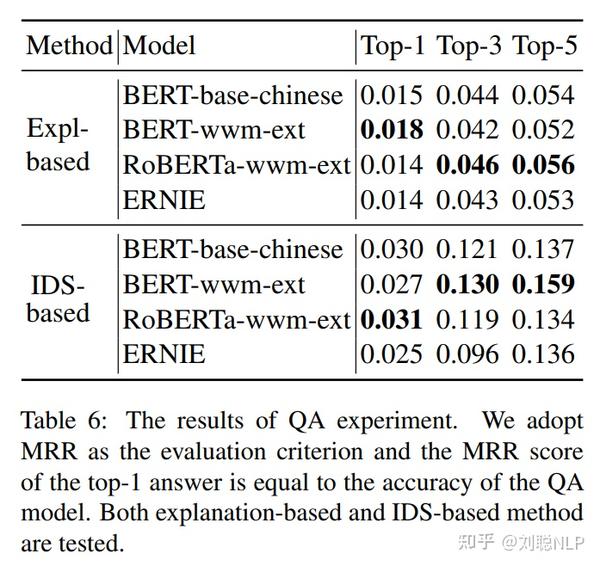
模型结果如下所示,在BERT、RoBERTa和ERNIE三种模型上,效果均不理想。
总结
算法工程师是厨子,算法是菜谱,数据是食材。普通食材只有好厨子能做出佳肴,但是好食材大多数厨子都能做出佳肴。
整理不易,请多多转发,点赞,关注,有问题的朋友也欢迎加我微信「logCong」私聊,交个朋友吧,一起学习,一起进步。
我们的口号是“生命不止,学习不停”。